Audio splitten mit mp3splt
Kennt das jemand? Man hat da ein Audio von mehreren Stunden und wenn man die Wiedergabe abbricht, muss man hinterher spulen? Ich kenne das ganz gut. Im Moment e...
Kennt das jemand? Man hat da ein Audio von mehreren Stunden und wenn man die Wiedergabe abbricht, muss man hinterher spulen? Ich kenne das ganz gut. Im Moment e...
In letzter Zeit werde ich immer wieder eine Sache gefragt: SSH ist ja ein tolles Ding, aber kann man nicht verhindern, dass alles abbricht, wenn man die Verbind...
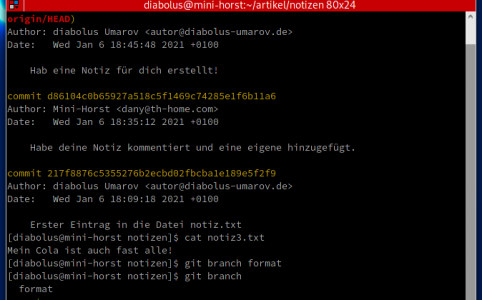
Git ist so eine kleine Wunderwaffe. Egal was man versionieren will, oder wenn man Backups erstellen möchte, oder ob man einfach mit mehreren Personen an etwas a...
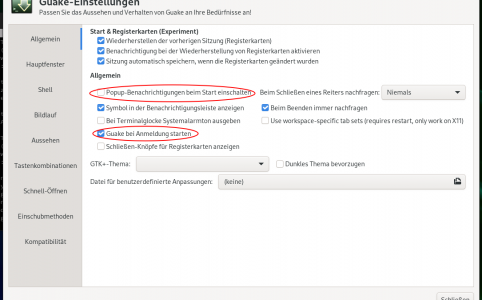
Ein kleiner Nachtrag zu Guake zum Thema Autostart. Auch wenn ich es im Artikel Terminals wie in Quake etwas anderes behauptet habe, will Guake mit der Methode ü...
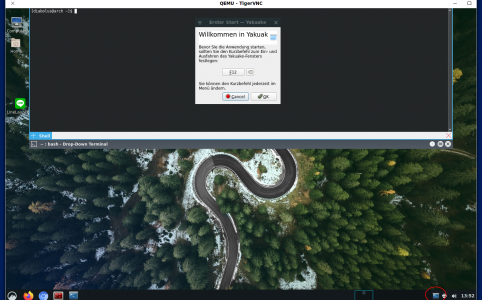
Korrekt müsste ich natürlich sagen, es geht um Terminal-Emulatoren, die an Quake angelehnt sind. Ich verwende, auch wenn es im Prinzip ja falsch ist, einfach nu...