Git ist so eine kleine Wunderwaffe. Egal was man versionieren will, oder wenn man Backups erstellen möchte, oder ob man einfach mit mehreren Personen an etwas arbeiten will, Git ist einfach der Hammer! Klein, schnell, super funktionell und sehr einfach zu beherrschen!
Ich sage aber eines vorweg. Das hier wird nur eine kurze Schritt für Schritt Anleitung, wie man schnell und einfach mit Git arbeiten kann. Wer tiefer in die Materie eintauchen will, mit Erklärungen wie was funktioniert, dem empfehle ich dieses Werk. Da schlage ich auch immer wieder gerne nach!
Was ist Git?
Lassen wir mal die üblichen Beschreibungen weg und nennen das Kind beim Namen. Wenn man an einem Projekt arbeitet, welches verschiedene Versionen haben wird, denn bekommt man mit Git ein mächtiges Ding an die Hand.
Programmieren
Als Beispiel. Sagen wir mal, man entwickelt eine Software. Version 1.0 war toll, 1.1 hat auch gerockt, 1.2 konnte ebenfalls überzeugen, aber mit 1.3 hat man so richtig Mist gebaut. Da steckt auf einmal so viel Schrott drin, den man im Leben nicht mehr von Hand ausgebaut bekommt. Treibt man sein Programm dabei in seinem Arbeitsverzeichnis voran, bleibt man aber auf diesem Stand stehen. Entweder fängt man bei 0 an, versucht 1.3 dann doch irgendwie zu retten, oder macht sich dann echt die Mühe, alle Änderungen seit Version 1.2 von Hand rückgängig zu machen.
Hat man mit Git jedoch für seine Versionen eigene Branches angelegt, sieht die Welt mit einem Mal viel freundlicher aus. Version 1.3 ist also Murks und rückgängig machen ist auch nicht. Also geht man einfach in den Branch 1.2 und arbeitet damit weiter. Eine sehr bequeme Sache!
Auch forken, also ein eigentlich fremdes Projekt nach seinen Wünschen anpassen, geht damit hervorragend. Man clont sich einfach den Code, legt einen neuen Branch an und los geht es. Ohne das Original zu verändern!
Backup / Cloud
Praktisch ist es aber auch, wenn man von bestimmten Dingen ein Backup erstellen möchte. Da sind Branches eher überflüssig, kann man aber definitiv auch verwenden.
Hat man seine Arbeit bis an den angestrebten Punkt voran getrieben, oder ist Backup-Tag, pusht man seine Arbeitskopie einfach auf den Server, oder wo auch immer man seine Gits liegen hat.
Das funktioniert auch beinahe wie eine Cloud. Sagen wir, normalerweise arbeitet man von seinem Desktop zuhause aus, pusht seine Änderungen nach getaner Arbeit und ist auf einmal irgendwo im Nirgendwo und hat Langeweile. Gut, da ist es dann natürlich praktisch, einen Laptop dabei zu haben.
Man clont sich einfach das Repository auf das Gerät, arbeitet, pusht anschliessend und pullt es zuhause wieder auf den Desktop. Einfach und bequem.
Gemeinsames Arbeiten
Viele werden das in Zusammenhang mit Git schon gehört haben. Da sich das jedoch eigentlich immer auf das programmieren bezieht, will ich mal ein anderes Beispiel hernehmen.
Sagen wir, da sind zwei Autoren, die am gleichen Buch arbeiten. Der Eine legt immer eine Szenerie in fünf Seiten grob vor, der Zweite arbeitet diese in den nächsten fünf Seiten weiter aus.
Autor 1 clont sich das Repository, schreibt seine fünf Seiten und pusht die im Anschluss zurück. Dann kommt Autor 2, pullt sich das Repository, schreibt wiederum seine fünf Seiten und pusht diese.
Am Ende ist das Buch fertig und vielleicht sitzen die Beiden dabei ewig viele Kilometer auseinander.
Installation
Zu installieren gibt es nicht viel. Man braucht eben Git. Oftmals ist das schon installiert, weil wirklich viele es einsetzen, aber falls nicht, muss man es eben doch hinzufügen.
sudo pacman -S gitSo sieht das bei Arch aus. Ich denke aber, wer sich schon an Git heranwagt, der weiss auch, wie man es installiert.
Versuchsaufbau
Man muss seine Repositorys nicht auf entfernten Rechnern auslagern. Das geht selbst verständlich auch lokal. Da ich aber davon ausgehe, dass die Meisten dann doch irgendwie gerne ihr Krempel extern auslagern, so können auch andere Beteiligen besser dran arbeiten, gehe ich auf eben diese Variante ein.
Wer es lokal machen will, der kann einfach den ssh Krempel weglassen.
Okay. Ziel der Übung wird es also sein, ein Repository auf meinem Raspberry anzulegen, es auf meinen Desktop zu klonen, etwas drin zu arbeiten und alles wieder auf den Raspberry zu schicken. Im Anschluss zeige ich dann noch das mit den Branches.
Da ich davon ausgehe, dass Nutzer, die nicht programmieren, es schwieriger haben werden, Programmcode zu verstehen, nehme ich einfach mal ein Beispiel, was nichts mit programmieren zu tun hat. Deshalb sage ich, wir wollen ein kleines Notizheft anlegen. Einfacher Klartext.
Vorbereitung
Git bietet eine ziemlich grosse Fülle an Einstellmöglichkeiten. So kann man beispielsweise auch einen bevorzugten Editor zum commiten angeben und ähnliches.
Wir wollen uns aber im Moment nur mit den wirklich notwendigen Dingen befassen.
Wer hätte es geahnt, wenn man mit verschiedenen Benutzern an einem Projekt arbeitet, würde man unter Umständen gerne wissen, wer wann welche Änderung vorgenommen hat. Da Git kein Hellseher ist, muss man ihm diese Informationen auch mitteilen.
git config --global user.name "John Doe"
git config --global user.email johndoe@example.comPeng. Das reicht schon. Einfach in den Terminal tippen, fertig. Natürlich sollte man anstatt “John Doe” und johndoe@example.com mit seinen eigenen Daten verwenden. Ja, hier kann man auch irgendwas eintragen. Wichtig ist eben, dass user.name und user.email in der Konfiguration vorhanden ist.
Da ich euch die Möglichkeit noch zeigen möchte, wie man commits mit einem Editor durchführt, sollten wir dieser Einstellung auch noch treffen.
git config --global core.editor nanoIch wähle deshalb nano, da der normalerweise eh installiert ist und sehr einfach bedient werden kann.
Zudem sollte man noch das Verhalten beim pullen einstellen. Sprich, was passieren soll, wenn etwas aus dem Repository entnommen wird.
git config --global pull.rebase falseFertig!
Ein Repository anlegen
Es macht natürlich Sinn, dass Repository direkt dort anzulegen, von wo man es hinterher clonen will. Zumindest mache ich das immer so. Auch macht es Sinn, einen eigenen Ordner für die Repositorys anzulegen. Muss man nicht, dient aber der Übersichtlichkeit.
Ich für meinen Teil habe dafür einen Ordner mit dem bezeichnenden Ordner git. Ja, ich bin schon sehr einfallsreich. Der liegt in meinem Home-Verzeichnis auf dem Raspberr und wartet auf seinen Einsatz. Da gehe ich jetzt rein.
Also. Da soll jetzt das Repository notizen angelegt werden.
Erster Schritt, hinsetzen! Ja, ja, irgendwann wird das Geheimnis hinter diesem Schritt gelöst.
Als Nächstes wird ein neues Verzeichnis angelegt, was sinnvoller Weise den Namen des Repositorys haben sollte.
mkdir notizenWer hier jetzt dankbar ist, dass ich diesen Schritt beschrieben habe, der sollte sich vielleicht zuerst einmal doch näher mit Linux beschäftigen.
Gut. In das Verzeichnis gehen wir nun rein und dort heisst es dann
git init
Die Hinweise sind tatsächlich nur Hinweise. Wir ignorieren die jetzt einfach. Wer sich damit näher beschäftigen will, siehe meinen Link am Anfang des Artikels.
Leeres Git-Repository in /home/diabolus/git/notizen/.git/ initialisiert
Warum erzählt der denn jetzt sowas? Ganz einfach. Man ist nicht darauf beschränkt, ein neues Repository in einem leeren Verzeichnis zu erstellen. Wer schon ein Arbeitsverzeichnis hat, was er nun gerne über Git verwalten würde, der kann auch direkt darin auf dem gleichen Weg ein Repository erstellen.
Seit ich jedoch mit Git arbeite, ist der erste Schritt bei allen Projekten immer das erstellen des Repositorys und, oh wunder, da ist das Verzeichnis dann eben leer.
Damit sind wir aber noch nicht ganz fertig, denn ein ganzes, reales Verzeichnis clont sich in meinen Augen ziemlich schlecht. Man sieht ja auch zum Beispiel auf Github, alles was man clont, ist eine Datei mit der Endung .git. Genau eine solche wollen wir auch!
Also wieder raus aus dem Verzeichnis und dann:
git clone --bare notizen
warning: Sie scheinen ein leeres Repository geklont zu haben.
Warum diese Meldung als Warnung gekennzeichnet ist, erschliesst sich mir nicht wirklich. Ich habe noch nie einen negativen Effekt gefunden, der auf ein leeres Repository zurückzuführen gewesen wäre. Einzig kann ich mir vorstellen, dass die Warnung ein Hinweis sein soll, um eventuell auf ein falsch angegebenes Verzeichnis hinzuweisen.

Schau an, da haben wir ja die Datei notizen.git, die wir nun ganz bequem clonen können.
Ich für meinen Teil lösche im Anschluss immer das Verzeichnis. Ist ja ohnehin leer und darin wird auch nicht mehr viel passieren. Wer jedoch ein bereits gefülltes Verzeichnis benutzt hat, will diesen Schritt wahrscheinlich gerne überspringen. Ist kein Problem! Einfach Verzeichnis bestehen lassen und gut ist.
Das Repository clonen
Da gibt es sehr viele Wege. Der Einfachste, für den man nicht noch gross was installieren und einrichten muss, ist ssh. Ich persönlich arbeite an meinen Projekten alleine, deshalb reicht es, wenn ich meinen Benutzer dafür verwende. Wer jedoch in einem Team arbeiten will, der sollte einen eigenen Benutzer für Git anlegen, dessen Zugangsdaten auch die Teammitglieder bekommen.
Wie man nun aber einen Benutzer anlegt, die Rechte vergibt und das alles, soll hier nicht Bestandteil das Artikels sein. Dafür gibt es schon X-Anleitungen im Netz und eigentlich hat jedes Linux irgendwo in seiner Anleitung diesen Schritt ebenfalls gut beschrieben drin.
Für diesen Artikel reicht es aber auch, wenn man mit seinem Benutzer den fernen Computer erreichen kann.
Auf dem Arbeitscomputer, in dem Verzeichnis seiner Wahl, kann man nun das Repository clonen. Dabei wird automatisch das entsprechende Verzeichnis angelegt! Würde man nun ein Verzeichnis notizen erstellen und dort drin das clonen durchführen, hätte man wieder ein Verzeichnis namens notizen. Ist also unsinnig.
git clone <benutzername>@<adresse>:/home/<benutzername>/git/notizen.gitNatürlich muss man <benutzername> und <adresse> mit seinen jeweiligen Daten ersetzen. In meinem Fall wäre das also:
git clone diabolus@piserver:/home/diabolus/git/notizen.git
Das hat ja hervorragend funktioniert! Natürlich wird man gebeten, dass Passwort einzugeben. Wäre ja auch zu schön, wenn da einfach jeder mal was clonen könnte.
Wer kein Passwort eingeben will, der kann hier auch Schlüssel generieren und die öffentlichen Schlüssel den jeweiligen Systemen bekannt machen. Darauf gehe ich hier aber nicht ein.
Im Repository arbeiten
Ja, wie arbeitet man nun damit? Ganz einfach! Genau so, wie man sonst auch arbeiten würde. Git ist es herzlich egal, mit welcher Software man hier was erstellt. Das spielt überhaupt keine Rolle.
Für unser Notizbuch reicht ein einfacher Editor. Egal ob grafisch, oder im Terminal. Spielt keine Rolle. Wichtig ist jedoch logischerweise, die Dateien müssen auch im Verzeichnis notizen liegen! Ich verwende einfach Nano und lege nun die Datei notiz.txt an.
nano notiz.txtDa schreibe ich jetzt etwas rein.

Das ist also der kleine Text, den ich in die Notiz geschrieben habe. Eben eine ganz einfache Text-Datei. Juckt Git alles nicht. Das frisst, was man ihm vorwirft.
Nun war das genug Notizen für heute. Ich will das so jetzt auch auf dem Server haben.
Das muss man Git dann auch sagen! Denn derzeit hat Git noch überhaupt keine Ahnung, was es mit dem komischen Text auf sich hat. Auf welchem Stand Git gerade ist, kann man so abfragen:
git status
Aha. Git hat also festgestellt, dass sich im Verzeichnis etwas geändert hat. Aber wir sind hier der Meister und nicht Git! Von daher übernimmt Git nicht automatisch alles, was man ihm so vorwirft. Wir müssen ihm sagen, was mit den Dateien, die Git bislang nicht kennt, oder die verändert wurden, passieren soll.
git add *Damit sagen wir Git, dass es alle Dateien übernehmen soll.

Ist das nicht nett von Git? Es sagt dazu einfach gar nichts. Hat es denn nun getan, was man von ihm verlangt hat? Fragen wir doch einfach wieder den Status ab.

Ausgezeichnet! Es gibt also Änderungen im Verzeichnis, die Git verwalten soll. Aber, wie ich ja gerade geschrieben hat, es hat sich etwas verändert! Um die Änderungen jetzt aber offiziell an Git zu übergeben, also zu commiten, müssen wir noch etwas tun. Eben es commiten! Dabei sollte man dann gleich noch eine gute Beschreibung hinzufügen, um es später besser nachvollziehen zu können.
git commit -m "Erster Eintrag in der Datei notiz.txt"
Ausgezeichnet! Damit sind wir mit der Arbeit auch schon fertig!
Das Repository veröffentlichen
Tatsächlich hat sich aber alles auf dem lokalen Computer abgespielt. Würde ein anderer Benutzer jetzt das Repository clonen, wäre von den Änderungen noch nichts zu sehen!
Das ist jedoch kein Bug, sondern ein Feature! Sagen wir, ein Autor ist mit seiner Arbeit noch nicht fertig, hat an dem Tag aber keine Lust mehr, noch etwas zu schreiben. Dann führt der seine Arbeit am nächsten Tag fort. Dennoch kann er die bisherigen Änderungen commiten. Vielleicht, um irgendwann einmal darauf zurückkommen zu können. Oder ein Programmierer hat die eigentliche Programmierung abgeschlossen, will aber alles erst einen Tag später noch sorgfältig testen, wenn er frisch und ausgeruht ist. Deshalb ist das veröffentlichen des Repository absichtlich eine manuelle Geschichte.
Das veröffentlichen ist aber sehr einfach. Wobei das Wort veröffentlichen hier vielleicht zu Missverständnissen führt. Natürlich veröffentlicht man seine Arbeit nicht sofort. Man aktualisiert quasi nur das Repository auf dem Server. Deshalb heisst es auch eigentlich push und nicht veröffentlichen.
git pushMagie, oder? Da ist es wirklich von Vorteil, dass wir alle in unserer Kindheit Raketenwissenschaft und Astronavigation studiert haben!

Im Team arbeiten
So. Da ist dann jetzt aber noch einer im Boot, der ebenfalls gerne mit dem Notizbuch arbeiten will. Ich simuliere das einfach mit meinem NetBook genannt Mini-Horst.
Was man dabei zuerst tut, sollte klar sein. Man setzt sich hin! Danach clont sich Mini-Horst das Repository, wie oben beschrieben. Er möchte eigene Notizen anlegen, aber liest auch die Notiz von Horst, sprich meinem Desktop. Da Mini-Horst ein gar lustiges Kerlchen ist, will er da einen Kommentar hinzufügen und editiert einfach mit dem Editor seiner Wahl die Datei notiz.txt.

Ach, er ist so nett, der Mini-Horst.
Gut. Nun will Mini-Horst aber eine weitere Notiz für sich erstellen und erstellt dafür die Datei notiz2.txt.

Ja! Cola ist wichtig!
Was sagt denn aber Git nun, wenn man den Status abfragt?

Genau! Git erkennt, dass die Datei notiz.txt geändert wurde und da noch eine neue Datei vorhanden ist, die es noch gar nicht kennt. Auch Mini-Horst muss seine Änderungen also adden, commiten und dann pushen.
Nun kommt wieder Horst, als mein Desktop. Vor der Arbeit will er checken, ob sich im Repository etwas getan hat. Das geht dann ganz einfach mit:
git pullAlso push (schieben), um etwas ins Repository zu bringen und pull (ziehen), um es zu aktualisieren.

Ach schau an, da ist ja was neues drin!
Git erkennt, wenn sich nichts geändert hat und meldet dann:
Bereits aktuell!Horst würde nun gerne wissen, was sich da geändert hat. Okay, bei zwei einfachen Textdateien kann man sich das noch schnell mal anschauen, bei grösseren Projekten kann das aber schnell unübersichtlich werden.
Aber war da nicht was mit commit? Musste man da nicht vor dem pushen was eingeben? Dann könnte man doch da mal nachschauen, was so passiert ist!
Richtung! Deshalb sollte man beim commiten auch wirklich hinschreiben, was man geändert hat. Das erhöht die Nachvollziehbarkeit.
Und wie macht man das jetzt? So:
git log
Na ist das nicht schön? Alle wichtigen Informationen sind da. Wer hat da was geändert, wann und was. Letzteres zumindest dann, wenn das jeweilige Team-Mitglied seinen Job auch ernst nimmt.
Aha. Der hat also die Notiz kommentiert. Schauen wir uns das doch einfach mal an!

Was ein Klugscheisser! Aber, was hat er denn da notiert?

Oh Cola! Muss ich gleich mal in der Garage schauen, ob ich noch genug habe!
Ich denke mal, damit sollte das arbeiten in einem Team mit git verständlich sein.
Arbeiten mit Branches
Gut. Die Beiden arbeiten also mit den Notizen und finden das ganz toll. Was aber, wenn da jetzt eine neue Notiz auftaucht, die Horst für Mini-Horst hinterlegt hat? Klar, Horst hat das natürlich brav beschrieben und Mini-Horst sieht im Log, dass eine Notiz extra für ihn erstellt wurde.

Nun kommt Mini-Horst aber auf eine Idee! Er will das Format der Notiz etwas ändern, damit aus dem Inhalt schon ersichtlich ist, um was es eigentlich geht.
Er könnte jetzt einfach eine neue Notiz erstellen, wo er das neue Format einfügt. Das würde er dann pushen und Horst bitten, sich das anzuschauen. Oder er editiert direkt die Notiz von Horst. Wäre auch möglich.
Beides hat aber eine Nachteil. In beidem Fall wird das eigentliche Projekt “zugemüllt”. Entweder erscheint da eine neue Notiz, oder Horst hat etwas in seiner Notiz stehen und findet das gar nicht gut. Wäre doch schön, wenn man Änderungen vornehmen könnte, ohne dabei das Original zu verkratzen!
Hier kommen Branches ins Spiel. Also Zweige, die vom Baum abgehen. Mini-Horst erstellt also zuerst mal einen neuen Branch mit dem Namen format.
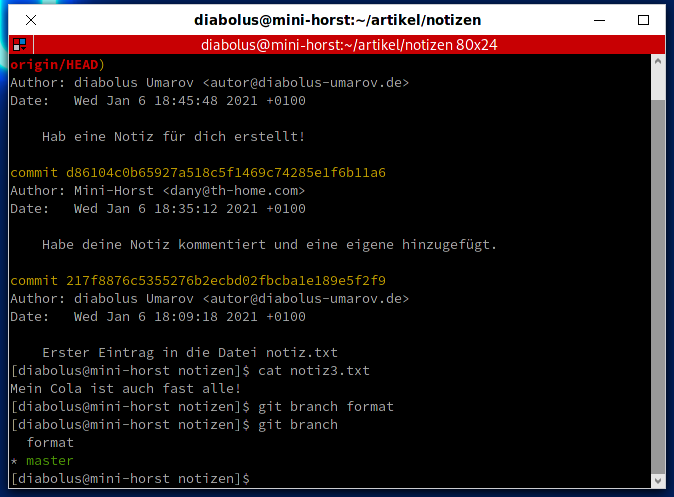
git branch format
Mit:
git branchkann man sich alle Branches anzeigen lassen. Jenes mit dem * ist das, in welchem man sich gerade befindet. Mini-Horst will nun in den neuen Branch wechseln.
git checkout format
Er ist also jetzt in einem neuen Zweig des Projektes. Mal schauen, ob sich im Ordner was verändert hat.

Nö. Alles so, wie man es erwarten würde!
Mini-Horst editiert jetzt die Datei notiz3.txt und baut dort seinen Vorschlag für ein neues Format ein.

So gefällt ihm das. Das muss nun kommentiert und gepusht werden.
Hier geht das pushen jedoch ein wenig anders. Der Grund dafür ist simpel. Nur weil man da an etwas herumspielt, muss das ja nicht gleich für jeden relevant, oder interessant sein. Unter Umständen tut man da etwas, nur um was herauszufinden, etwas zu versuchen usw. Deshalb muss man einen Branch auch extra pullen.
git pull origin formatNun kommt Horst daher, pullt alles und schreibt schnell was in die Datei notiz.txt, ohne sich um die Änderungen im Repository zu kümmern. Was heisst er kümmert sich nicht um die Änderungen? Er bekommt ja gar keine angezeigt! Das heisst, er bekommt trotz pull nichts von dem neuen Branch mit.
Das merkt dann auch Mini-Horst und will Horst trotzdem mitteilen, dass es da eine Änderung gibt. Also schreibt er es in die Datei notiz4.txt. Aber wieder unter dem Branch master, nicht unter format. Commiten, pushen und abwarten.
Horst pullt wieder und ihm fallen Änderungen auf. Er schaut in die Logs.

Hier fällt nun etwas auf. Die Ausgabe ist länger, als der Terminal hoch ist. Deshalb erscheinen unten die Doppelpunkte. Drückt man Enter, geht es nach unten weiter. Das kennt man aber wahrscheinlich schon und drückt deshalb einfach q.
Aha. Mini-Horst hat also einen Formatforschlag gemacht im Branch format. Schauen wir uns das doch einmal an.

Öhm. Es gibt aber gar keinen Branch namens format. Dann muss Horst den wohl manuell abholen.
git fetch origin format
Das hat ja geklappt. Dann muss der Branch ja jetzt da sein.

Mysteriös. Er ist nicht da! Was passiert denn aber, wenn man einfach in den Branch wechselt? Angeblich ist er ja heruntergeladen worden.

Ach ne. Da ist er ja! Ausserdem hat Git uns auch gleich in den Branch gewechselt. Interessant! Dann schauen wir doch mal, was Mini-Horst da vorgeschlagen hat!

Ah! Von, An, ja, sieht übersichtlicher aus. Machen wir so! Aber, ist das jetzt schon direkt so auch in der Datei notiz3.txt in master?

Nein! Das heisst, hätte Mini-Horst jetzt da irgendeinen unsinnigen Schwachsinn eingebaut, hätte man den Branch einfach löschen können und nichts weiter wäre passiert.
Aber gut. Was Mini-Horst da gemacht hat, was gut und ist sinnvoll. Aber muss Horst das jetzt in der Datei notiz3.txt so abtippen? Natürlich nicht!
Man kann ganz einfach die Änderungen übernehmen. Dazu muss man sich im Branch master befinden.
git merge format
Ach da schau her! Automatisch wird der eingangs ausgewählte Editor gestartet und man wird aufgefordert, den Grund für das Zusammenführen (merge) zu beschreiben. Prima, macht Horst doch gerne!

Nachdem die Beschreibung gespeichert wurde und der Editor wieder zu ist, werden die Änderungen übernommen. Aber Vertrauen ist gut, Kontrolle ist besser. Also schauen wir zuerst, ob wir im Branch master sind und ob die Datei notiz3.txt nun auch wirklich die Änderungen übernommen hat.

Jawohl, hat hervorragend funktioniert! Das kann man jetzt pushen und fertig.
Anmerkung:
Ich arbeite noch nicht so lange mit Branches. Es liegt deshalb im Bereich des Möglichen, dass man damit auch einfacher arbeiten kann. Sollte ich dafür einen Weg finden, dann werde ich das hier aktualisieren.
Falls mich dabei aber jemand unterstützen kann, eine Mail würde mich freuen.
Zum Schluss
Git kann einem die Arbeit wirklich erleichtern. Es macht genau das was es soll und man muss sich an keine Restriktionen halten. Ich habe mir schon Videos zu anderen Versionierungssysteme angeschaut und hab mich jedes Mal gefragt, warum man das einsetzen sollte. Da werden unter Umständen die Arbeitsweisen vorgegeben, jeder Branch ist gleich ein komplettes Verzeichnis mit allen Dateien, was bei grossen Projekten Zeit und Speicherplatz kostet, oder man bekommt direkt eine komplette Umgebung vorgesetzt, wo man nur mit den jeweiligen, vorgeschriebenen Tools arbeiten kann.
Git macht nichts davon. Eigentlich merkt man gar nicht, dass Git da ist, solange man nicht pullt, pusht, oder commitet. Das ist auch gut so. Es tritt nur dann in Erscheinung, wenn man es braucht und wenn man selbst entschieden hat, dass man es nun einsetzen will.