Nächster Fortschritt bei WSC
Ja, im Moment läuft es! Aktueller Stand: Umstellung von pqxx auf QtSql durchgeführt Funktionsfähigkeit unter Windows geprüft Registrierung funktioniert Schlüsse...
Ja, im Moment läuft es! Aktueller Stand: Umstellung von pqxx auf QtSql durchgeführt Funktionsfähigkeit unter Windows geprüft Registrierung funktioniert Schlüsse...
Das ist nur ein kleines Update, um den Stand der Dinge zu klären. Zum Einen, ich habe ein paar Änderungen vorgenommen. Sollte ursprünglich noch pqxx für die Ver...
In letzter Zeit werde ich immer wieder eine Sache gefragt: SSH ist ja ein tolles Ding, aber kann man nicht verhindern, dass alles abbricht, wenn man die Verbind...
Ja, es geht wirklich immer weiter! Mit Version 0.4 ist nun die erste nutzbare Version fertig. Alle grundlegende Funktionen sind enthalten und funktionieren! Im ...
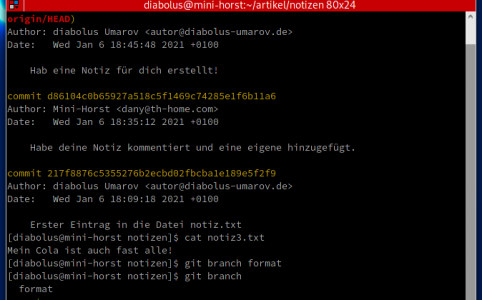
Git ist so eine kleine Wunderwaffe. Egal was man versionieren will, oder wenn man Backups erstellen möchte, oder ob man einfach mit mehreren Personen an etwas a...
Und es geht weiter! Das Projekt ist schon so jung und dennoch gibt es deutliche Veränderungen zur Version 0.2. Das Passwort ist aus den Einstellungen geflogen. ...
Das Netzwerk ist ja schon eine tolle Sache. Rein theoretisch kann man von überall auf seinen Computer zugreifen, Daten entnehmen, an Projekten arbeiten, Wartung...